|
|
要求开发一个模型, 这个模型只使用到目前为止的过去的每日价格流来确定,每天应该买入、 持有还是卖出他们投资组合中的资产。 2016 年 9 月 11 日, 将从 1000 美元开始。 将使用五年交易期, 从 2016 年 9 月 11 日到2021 年 9 月 10 日。 在每个交易日, 交易者的投资组合将包括现金、 黄金和比特币[C, G, B],分别是美元、 金衡盎司和比特币。 初始状态为[1000,0,0]。 每笔交易(购买或销售)的佣金是交易金额的α%。 假设

=1%,

= 2%。 持有资产没有成本。 请注意, 比特币可以每天交易, 但黄金只在市场开放的日子交易(即周末不交易), 这反映在定价数据文件LBMA-GOLD.csv 和 BCHAIN-MKPRU.csv 中。 你的模型应该考虑到这个交易计划, 但在建模过程中你只能使用其中之一。
开发一个模型, 仅根据当天的价格数据给出最佳的每日交易策略。 使用你的模型和策略, 在 2021 年 9 月 10 日最初的 1000 美元投资价值多少?
提供证据证明你的模型提供了最佳策略。
确定该策略对交易成本的敏感度。 交易成本如何影响战略和结果?
将你的策略、 模型和结果以一份不超过两页的备忘录的形式传达给交易者。 注意: 您的 PDF 总页数不超过 25 页, 解决方案应包括:
一页摘要表。 目录。 完整的解决方案。 一到两页附录。 参考文献。
注:MCM 竞赛有 25 页的限制。 您提交的所有方面都计入 25 页的限制(摘要页、 目录、 参考文献和任何附录)。 必须在你的报告中标注你的想法、 图像和其他材料的来源引用
2 思路解析
3 Python 实现
3.1 数据分析和预处理
(1)数据分析
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
gold = pd.read_csv( amp;#39;./data/LBMA-GOLD.csv amp;#39;)
bitcoin = pd.read_csv( amp;#39;./data/BCHAIN-MKPRU.csv amp;#39;)
gold.info() RangeIndex: 1265 entries, 0 to 1264 Data columns (total 2 columns):
Column Non-Null Count Dtype --- ------ -------------- -----
0 Date 1265 non-null object
1 USD (PM) 1255 non-null float64
dtypes: float64(1), object(1)
# 缺失值查看
gold.isnull().any() Date False
USD (PM) True
dtype: bool
黄金序列存在缺失值
bitcoin.isnull().any() Date False
Value False
dtype: bool
比特币序列没有缺失值
可视化数据
x1 = range(len(gold))
y1 = gold[ amp;#39;USD (PM) amp;#39;]
x2 = range(len(bitcoin))
y2 = bitcoin[ amp;#39;Value amp;#39;]
plt.plot(x1,y1)
plt.plot(x2,y2,color= amp;#39;r amp;#39;)
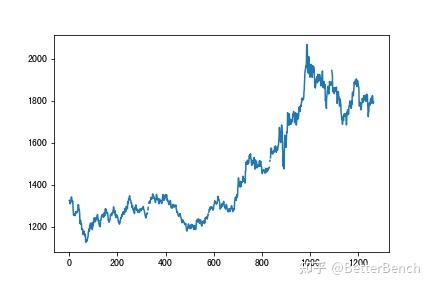
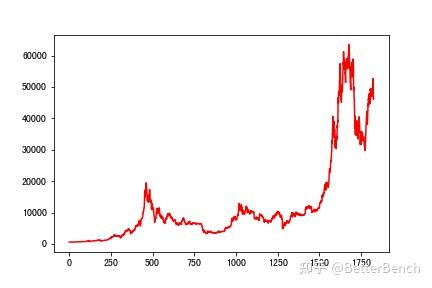
(2)数据预处理
黄金序列是有缺失值,且周末不存在数据,时间序列是中断的,以下采用插值法进行填充数据,将补充为完整的时间序列
gold.index = list(pd.DatetimeIndex(gold.Date))
gold_datalist = pd.date_range(start= amp;#39;2016-09-12 amp;#39;,end= amp;#39;2021-09-10 amp;#39;)
ts = pd.Series(len(gold_datalist)*[np.nan],index=gold_datalist)
gold_s = gold[ amp;#39;USD (PM) amp;#39;]
for i in gold.index:
ts = gold_s
# 线性插值法
ts = ts.interpolate(method= amp;#39;linear amp;#39;)
gold_df = ts.astype(float).to_frame()
gold_df.rename(columns={0: amp;#39;USD amp;#39;},inplace=True)
gold_df.sort_index()
gold_df.index = range(len(gold_df))
gold_df补充完整后,黄金的时间序列有1825条数据
3.2 预测
(1)特征工程
# 提取特征
from tsfresh import extract_features, extract_relevant_features, select_features
from tsfresh.utilities.dataframe_functions import impute
gold_df[ amp;#39;id amp;#39;] = range(len(gold_df))
extracted_features = extract_features(gold_df,column_id= amp;#39;id amp;#39;)
extracted_features.index = gold_df.index
# 去除NAN特征
extracted_features2 = impute(extracted_features)构造训练集
import re
# 向未来移动一个时间步长
timestep = 1
Y = list(gold_df[ amp;#39;USD amp;#39;][timestep:])
X_t = extracted_features2[:-timestep]
X = select_features(X_t, np.array(Y), fdr_level=0.5)
X = X.rename(columns = lambda x:re.sub( amp;#39;[^A-Za-z0-9_]+ amp;#39;, amp;#39; amp;#39;, x))(2)模型训练预测
# 划分30%作为测试集
s = 0.3
tra_len = int((1-s)*len(X))
test_len = len(X)-tra_len
X_train, X_test, y_train, y_test = X[0:tra_len], X[-test_len:], Y[0:tra_len],Y[-test_len:]
# 方法一
import lightgbm as lgb
# clf = lgb.LGBMRegressor(
# learning_rate=0.01,
# max_depth=-1,
# n_estimators=5000,
# boosting_type= amp;#39;gbdt amp;#39;,
# random_state=2022,
# objective= amp;#39;regression amp;#39;,
# )
# clf.fit(X=X_train, y=y_train, eval_metric= amp;#39;MSE amp;#39;, verbose=50)
# y_predict = clf.predict(X_test)
# 方法二
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
linreg = LinearRegression()
model = linreg.fit(X_train, y_train)
y_pred = linreg.predict(X_test)预测及输出评价指标
from sklearn import metrics
def metric_regresion(y_true,y_pre):
mse = metrics.mean_squared_error(y_true,y_pre)
mae = metrics.mean_absolute_error(y_true,y_pre)
rmse = np.sqrt(metrics.mean_squared_error(y_true,y_pre)) # RMSE
r2 = metrics.r2_score(y_true,y_pre)
print( amp;#39;MSE:{} amp;#39;.format(mse))
print( amp;#39;MAE:{} amp;#39;.format(mae))
print( amp;#39;RMSE:{} amp;#39;.format(rmse))
print( amp;#39;R2:{} amp;#39;.format(r2))
metric_regresion(y_test,y_pred) MSE:267.91294723114646
MAE:10.630377450265746
RMSE:16.368046530699576
R2:0.9707506268528148
可视化预测结果
import matplotlib.pyplot as plt
plt.figure()
plt.plot(range(len(y_pred[100:180])), y_pred[100:180], amp;#39;b amp;#39;, label= amp;#34;预测 amp;#34;)
plt.plot(range(len(y_test[100:180])), y_test[100:180], amp;#39;r amp;#39;, label= amp;#34;原始 amp;#34;)
plt.legend(loc= amp;#34;upper right amp;#34;, prop={ amp;#39;size amp;#39;: 15})
plt.show()
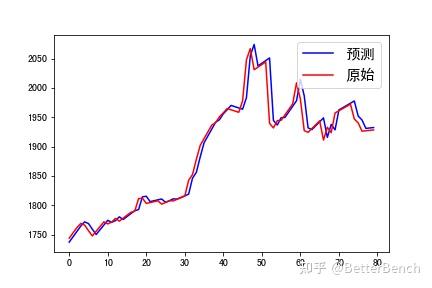
3.3 进阶的预测方案和代码
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings( amp;#39;ignore amp;#39;)
import statsmodels.api as sm
import matplotlib.pyplot as plt
import matplotlib as mpl
import itertools
plt.style.use( amp;#34;fivethirtyeight amp;#34;)
gold = pd.read_csv( amp;#39;LBMA-GOLD.csv amp;#39;)
bitcoin = pd.read_csv( amp;#39;BCHAIN-MKPRU.csv amp;#39;)
gold.index = list(pd.DatetimeIndex(gold.Date))
bitcoin.index = list(pd.DatetimeIndex(bitcoin.Date))
bitcoin[ amp;#39;Date amp;#39;] = bitcoin.index
gold[ amp;#39;Date amp;#39;] = gold.index
y=bitcoin[ amp;#34;Value amp;#34;].resample( amp;#34;MS amp;#34;).mean()#获得每个月的平均值
print(y.isnull().sum)#5个 检测空白值
#处理数据中的缺失项
y=y.fillna(y.bfill())#填充缺失值
plt.figure(figsize=(15,6))
plt.title( amp;#34;intial amp;#34;,loc= amp;#34;center amp;#34;,fontsize=20)
plt.plot(y)
#找合适的p d q
#初始化 p d q
p=d=q=range(0,2)
print( amp;#34;p= amp;#34;,p, amp;#34;d= amp;#34;,d, amp;#34;q= amp;#34;,q)
#产生不同的pdq元组,得到 p d q 全排列
pdq=list(itertools.product(p,d,q))
print( amp;#34;pdq:\n amp;#34;,pdq)
seasonal_pdq=[(x[0],x[1],x[2],12) for x in pdq]
print( amp;#39;SQRIMAX:{} x {} amp;#39;.format(pdq[1],seasonal_pdq[1]))
# 时间序列搜索最优参数(比特币为例,黄金同理)
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param, seasonal_order=param_seasonal, enforce_stationarity=False, enforce_invertibility=False)
results = mod.fit()
print( amp;#39;ARIMA{}x{}12 - AIC:{} amp;#39;.format(param, param_seasonal, results.aic))
except:
continue
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 0, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])
results.plot_diagnostics(figsize=(15, 12))
plt.show()
# #进行验证预测
pred=results.get_prediction(start=pd.to_datetime( amp;#39;2017-01-01 amp;#39;),dynamic=False)
pred_ci=pred.conf_int()
print( amp;#34;pred ci:\n amp;#34;,pred_ci)#获得的是一个预测范围,置信区间
print( amp;#34;pred:\n amp;#34;,pred)#为一个预测对象
print( amp;#34;pred mean:\n amp;#34;,pred.predicted_mean)#为预测的平均值
#进行绘制预测图像
plt.figure(figsize=(10,6))
ax=y[ amp;#39;1990 amp;#39;:].plot(label= amp;#34;observed amp;#34;)
pred.predicted_mean.plot(ax=ax,label= amp;#34;static ForCast amp;#34;,alpha=.7,color= amp;#39;red amp;#39;,linewidth=2)
#在某个范围内进行填充
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color= amp;#39;k amp;#39;, alpha=.2)
ax.set_xlabel( amp;#39;Date amp;#39;)
ax.set_ylabel( amp;#39;bi Levels amp;#39;)
plt.legend()
plt.show()
pred_dynamic = results.get_prediction(start=pd.to_datetime( amp;#39;2017-01-01 amp;#39;), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()
# #使用动态预测
pred_dynamic = results.get_prediction(start=pd.to_datetime( amp;#39;2017-01-01 amp;#39;), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()
ax = y[ amp;#39;2017 amp;#39;:].plot(label= amp;#39;observed amp;#39;, figsize=(20, 15))
pred_dynamic.predicted_mean.plot(label= amp;#39;Dynamic Forecast amp;#39;, ax=ax)
ax.fill_between(pred_dynamic_ci.index,
pred_dynamic_ci.iloc[:, 0],
pred_dynamic_ci.iloc[:, 1], color= amp;#39;k amp;#39;, alpha=.25)
ax.fill_betweenx(ax.get_ylim(), pd.to_datetime( amp;#39;2017-01-01 amp;#39;), y.index[-1],
alpha=.1, zorder=-1)
ax.set_xlabel( amp;#39;Date amp;#39;)
ax.set_ylabel( amp;#39;bi Levels amp;#39;)
plt.legend()
plt.show()
# Get forecast 500 steps ahead in future
pred_uc = results.get_forecast(steps=200)#steps 可以代表(200/12)年左右
# Get confidence intervals of forecasts
pred_ci = pred_uc.conf_int()
plt.title( amp;#34;预测 amp;#34;,fontsize=15,color= amp;#34;red amp;#34;)
ax = y.plot(label= amp;#39;observed amp;#39;, figsize=(20, 15))
pred_uc.predicted_mean.plot(ax=ax, label= amp;#39;Forecast amp;#39;)
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color= amp;#39;k amp;#39;, alpha=.25)
ax.set_xlabel( amp;#39;Date amp;#39;,fontsize=15)
ax.set_ylabel( amp;#39;bi Levels amp;#39;,fontsize=15)
plt.legend()
plt.show()
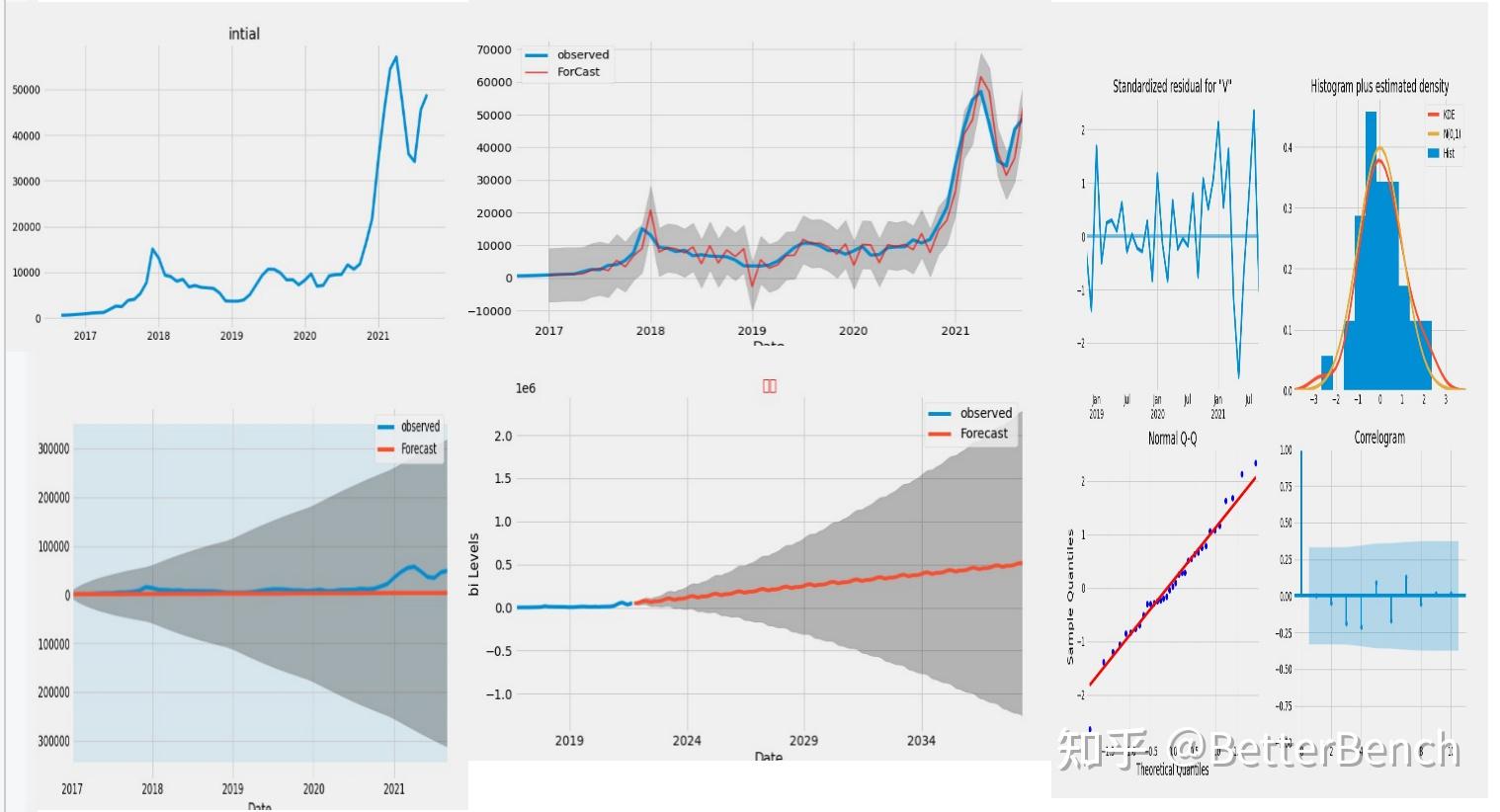
完整数学模型和代码下载
3.4 动态规划
3.4.1 思路1
符号说明

初始买入比例

前后一天价格

前后一天价格差

变化收益
b% 中途卖出比例(也是买入比例)
目标函数:

约束条件:
1、

(成本约束)(买出卖出成本)
2、

3、

(持有会带来的成本)
4、

风险系数约束(可用预测模型的置信区间权衡风险)
3.4.2 思路2
符号说明
目标函数

i表示第i天的交易,取值1到n
j表示是否是周末,取值0或1,0表示不是周末, 1表示周末
gain_i表示第i天的最大收益

表示第i天的黄金价格

表示第i天的比特币价格

表示第i天购入的黄金数量,单位美元/盎司

表示第i天购入的比特币数量,单位美元/个

约束条件






3.4.3 思路3
我们用buy表示在最大化收益的前提下,如果我们手上拥有一支股票,那么它的最低买入价格是多少。在初始时,buy 的值为prices[0] 加上手续费fee。那么当我们遍历到第 i (i 0) 天时:
如果当前的股票价格prices 加上手续费fee 小于buy,那么与其使用buy 的价格购买股票,我们不如以prices+fee 的价格购买股票,因此我们将buy 更新为prices+fee;
如果当前的股票价格prices 大于buy,那么我们直接卖出股票并且获得pricesbuy 的收益。但实际上,我们此时卖出股票可能并不是全局最优的(例如下一天股票价格继续上升),
因此我们可以提供一个反悔操作,看成当前手上拥有一支买入价格为 prices 的股票,将buy 更新为prices。这样一来,如果下一天股票价格继续上升,
我们会获得prices[i+1]prices 的收益,加上这一天pricesbuy 的收益,恰好就等于在这一天不进行任何操作,而在下一天卖出股票的收益;
对于其余的情况,prices 落在区间[buyfee,buy] 内,它的价格没有低到我们放弃手上的股票去选择它,也没有高到我们可以通过卖出获得收益,因此我们可以卖出去交易比特币。
上面的贪心思想可以浓缩成一句话,即当我们卖出一支股票时,我们就立即获得了以相同价格并且免除手续费买入一支股票的权利。在遍历完整个数组prices 之后之后,我们就得到了最大的总收益。
3.4.2 Python 实现
代码下载
你这是不是直接预测价格了? 需要改成预测收益率。另外填充缺失数据别用线性插值,会有未来函数,直接用上一期的更真实
对啊hh,所以我们用了lstm和arima,arima数据少的时候用,后面数据多了训练lstm能收敛了就用lstm。
你要是百分之百预测准确,你就能够找到唯一一种收益最大的策略。(只要涨幅高于手续费就全买,跌幅超过手续费就全卖),正因为预测不准确,所以才要你整个策略出来来看如何折中收益和预测模型带来的风险
这不扯淡吗,你在有限时空内又不知道比特币的总体趋势是上升的,明显不就是开了上帝视角吗[飙泪笑]
只是举了个反例,因为我们每天都会去用当天的训练数据,去训练一个预测模型,我们策略会根据这个预测模型的历史上的准确度和预测结果来设置我们的策略。后面测试下来,即使预测模型与真实值的bias在0.08都能保证50倍的收益,但因为我们预测模型的bias只在0.4左右,所以我们收益有300倍 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有帐号?立即注册
x
|




 发表于 2022-9-5 00:45:06
发表于 2022-9-5 00:45:06
